응용편 및 참고 자료
지금까지 Caffe를 가지고 라벨링된 이미지를 통해 모델을 훈련시키고 이렇게 훈련된 모델을 새로운 이미지에 적용하여 분류하는 방법을 알아보았다.
그럼 이걸 실시간으로 들어오는 영상에 집어넣고 분류하도록 할 수 있을까?
방법은 의외로 간단하다. Python 에서 돌아가는 Opencv 가 있으니까.
파이썬에서 caffe.Net 을 통해 모델을 불러오고 transformer에 이미지 변환하고 입출력하는 부분을 구현하는 것은 동일하다.
단지 카메라 영상을 가져오기만 하면 된다.
놀랍게도 파이썬에서는 cv2.VideoCapture(0) 라는 간단한 선언만으로 카메라를 열고 영상을 받아올 수 있다.
아래는 영상을 열고 분류를 하는 코드이다.
while 문 무한루프 안에서 영상을 받고 분류하는 과정의 반복이다. 키보드에서 'q'를 누르면 빠져나오게 된다.
#Start capture video from Camera
cap = cv2.VideoCapture(0)
while(True):
# Capture frame-by-frame
ret, frame = cap.read()
img = transform_img(frame, img_width=IMAGE_WIDTH, img_height=IMAGE_HEIGHT)
net.blobs['data'].data[...] = transformer.preprocess('data', img)
out = net.forward()
pred_probas = out['prob']
argmax = pred_probas.argmax()
if argmax == 1:
scr_msg = 'Looks like DOG with Probability of {:0.2f}'.format(pred_probas[0][1])
else:
scr_msg = 'Looks like CAT with Probability of {:0.2f}'.format(pred_probas[0][0])
# Set Display message
img_H, img_W = frame.shape[:2]
cv2.rectangle(frame, (0,int(img_H*0.9)), (img_W, img_H), (255,255,255), -1)
bottomLeftCornerOfText = (int(img_W * 0.05), int(img_H * 0.96))
cv2.putText(frame, scr_msg,
bottomLeftCornerOfText,
font,
fontScale,
fontColor,
lineType)
# Display the resulting frame
cv2.imshow('frame',frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
전체 코드는 깃허브의 아래 페이지에 나와있으므로 기존에 튜토리얼을 전부 달성했다면 쉽게 돌려볼 수 있다.
https://github.com/kyuhyong/deep_learning_caffe/blob/master/pycode/rt_classification.py
이제 웹캠을 통해서 나의 얼굴이 개에 가까운지, 또는 고양이에 가까운지 확인할 수 있다. ;)
하지만 이 식별 알고리즘은 몇가지 문제가 있다. 지금 현재 들어온 영상의 어느 부분을 인식하고 판단을 내리는지. 극 배경과 사물의 분리, 물체의 위치등을 검출하지 못한다.
단지 이미지의 전체적인 형상을 가지고 판단을 내리게 되므로 개와 고양이가 동시에 있는 영상을 판단하지 못하게 된다.
그래서 전세계의 많은 딥러닝 연구가들이 이러한 문제를 해결하기 위해 여러가지 방법을 고안해 냈다. 그중에서 대표적인 방법 세가지를 꼽아보면 다음과 같다.
- Faster R-CNNs (Girshick et al., 2015)
- You Only Look Once (YOLO) (Redmon and Farhadi, 2015)
- Single Shot Detectors (SSDs) (Liu et al., 2015)

Figure 1: Examples of object detection using Single Shot Detectors (SSD) from Liu et al.
Faster R-CNN(R은 Region Proposal을 의미한다)과 같은 방법이 있지만 사실 깊이있는 연구가가 아니면 일반인이 이해하기도 어렵고 모델을 훈련시키기도 쉽지 않다. 간단히 설명하면 사진에서 의가 있을법한 곳을 구역 구역으로 쪼개서 딥러닝 모델을 돌리는 방법인데 비록 Faster라는 이름이 붙어있긴 하지만 속도를 빠르게 하는것이 쉽지 않다. 대략 7 PFS 정도가 나온다고 한다.
만약 정확성을 약간 포기하고 속도에 중점을 둔다면 YOLO같은 방법을 사용하는것이 유리할 수 있다. Titan X와 같은 최고 성능의 PC에서 돌릴경우 최대 155FPS까지 도달한다고 한다. (https://www.pyimagesearch.com/2017/09/11/object-detection-with-deep-learning-and-opencv/)
SSD 알고리즘은 구글에서 개발되기 시작하였고 R-CNN과 YOLO 사이에서 적당한 정확도와 빠르기를 보여준다 Girshick et al. 이 알고리즘은 좀더 이해하기 쉽고 구조가 명확하다. 사용하는 네트웍 구조에 따라 22-46FPS 가 나오기도 한다. SSD에 대한 보다 자세한 내용은 Liu et al 의 논문을 참조하면 된다.
아래는 이렇게 동작하는 알고리즘의 한 예이다.
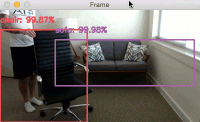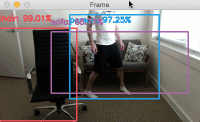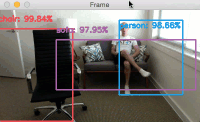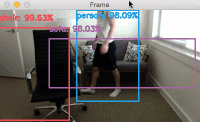
2018/1/24 최초문서 발행됨.
'ROBOTICS > Artificial Intelligence' 카테고리의 다른 글
| Theano 설치하기 (0) | 2018.04.11 |
|---|---|
| Ubuntu 16.04 에 Tensorflow 소스로부터 설치하기(GPU from source) (0) | 2018.01.30 |
| Caffe 와 Python을 사용하여 딥러닝으로 개와 고양이 구분하기[2] (6) | 2018.01.18 |
| Caffe 와 Python을 사용하여 딥러닝으로 개와 고양이 구분하기[1] (2) | 2018.01.17 |
| Ubuntu 16.04 에 Caffe 설치하기(GPU with CUDA) (0) | 2018.01.11 |